Introduction
Rule 1:- What is the Nature of the application(OLTP or OLAP)?
Rule 2:- Break your data in to logical pieces, make life simpler
Rule 3:- Do not get overdosed with rule 2
Rule 4:- Treat duplicate non-uniform data as your biggest enemy
Rule 5:- Watch for data separated by separators.
Rule 6:- Watch for partial dependencies.
Rule 7:- Choose derived columns preciously
Rule 8:- Do not be hard on avoidingredundancy, if performance is the key
Rule 9:- Multidimensional data is a different beast altogether
Rule 10:- Centralize name value table design
Rule 11:- For unlimited hierarchical data self-reference PK and FK

Courtesy: - Image from Motion pictures
IntroductionBefore you start reading this article let me confirm that I am not a guru in database designing. The below 11 points which are listed are points which I have learnt via projects, my own experiences and my own reading. I personally think it has helped me a lot when it comes to DB designing. Any criticism welcome.
The reason why I am writing a full blown article is, when developers sit for designing a database they tend to follow the three normal forms like a silver bullet. They tend to think normalization is the only way of designing. Due this mind set they sometimes hit road blocks as the project moves ahead.
In case you are new to normalization, then click and see 3 normal forms in action which explains all three normal forms step by step.
Said and done normalization rules are important guidelines but taking them as a mark on stone is calling for troubles. Below are my own 11 rules which I remember on the top head while doing DB design.
Rule 1:- What is the Nature of the application(OLTP or OLAP)?
When you start your database design the first thing to analyze is what is the natureof theapplication you are designing for, is it Transactional or Analytical. You will find many developers by default applying normalization rules without thinking about the nature of the application and then later getting in to performance and customization issues. As said there are 2 kinds of applications transaction based and analytical based,let's understand what these types are.
Transactional: - In this kind of application your end user is more interested in CRUD i.e. Creating, reading, updating and deleting records. The official name for such kind of database is called as OLTP.
Analytical: -In these kinds of applications your end user is more interested in Analysis, reporting, forecasting etc. These kinds of databases have less number of inserts and updates. The main intention here is to fetch and analyze data as fast as possible. The official name for such kind of databases is OLAP.

Below is a simple diagram which shows how the names and address in the left hand side is a simple normalized table and by applying denormalized structure how we have created a flat table structure.

This rule is actually the 1st rule from 1st normal formal. One of the signs of violation of this rule is if your queries are using too many string parsing functions like substring, charindexetc , probably this rule needs to be applied.
For instance you can see the below table which has student names , if you ever want to query student name who is having "Koirala" and not "Harisingh" , you can imagine what kind of query you can end up with.
So the better approach would be to break this field in to further logical pieces so that we can write clean and optimal queries.

Developers are cute creatures. If you tell them this is the way, they keep doing it; well they overdo it leading to unwanted consequences. This also applies to rule 2 which we just talked above. When you think about decomposing, give a pause and ask yourself is it needed. As said the decomposition should be logical.
For instance you can see the phone number field; it's rare that you will operate on ISD codes of phone number separately(Until your application demands it). So it would be wise decision to just leave it as it can lead to more complications.

Focus and refactor duplicate data. My personal worry about duplicate data is not that it takes hard disk space, but the confusion it creates.
For instance in the below diagram you can see "5th Standard" and "Fifth standard" means the same. Now you can say due to bad data entry or poor validation the data has come in to your system. Now if you ever want toderive a report they would show them as different entities which is very confusing from end user point of view.


The second rule of 1st normal form says avoid repeating groups. One of the examples of repeating groups is explained in the below diagram. If you see the syllabus field closely, in one field we have too much data stuffed.These kinds of fields are termed as "Repeating groups". If we have to manipulate this data, the query would be complex and also I doubt performance of the queries.

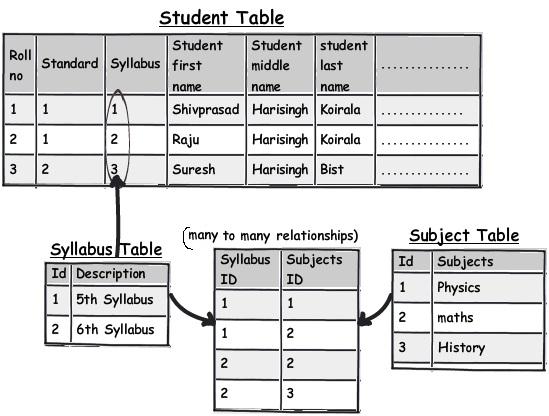
With this approach the syllabus field in the main table is no more repeating and having data separators.
Rule 6:- Watch for partial dependencies.
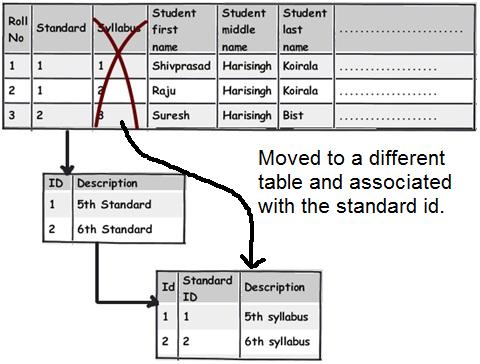
Syllabus is associated with the standard in which the student is studying and not directly with the student. So if tomorrow we want to update syllabus we have to update for each student which is pain staking and not logical. It makes more sense to move these fields out and associate them with the standard table.
You can see how we have move the syllabus field and attached the same to standards table.
This rule is nothing but second normal form "All keys should depend on the full primary key and not partially".
Rule 7:- Choose derived columns preciously

In the above figure you can see how average field is dependent on marks and subject. This is also one of form of redundancy. So for such kind of fields which are derived from other fields give a thought are they really necessary.
This rule is also termed as 3rd normal form "No columns should depend on other non-primary key columns". My personal thought is do not apply this rule blindly see the situation; it's not that redundant data is always bad. If the redundant data is calculative data , see the situation and then decide do you want to implement the third normal form.
Rule 8:- Do not be hard on avoidingredundancy, if performance is the key

Rule 9:- Multidimensional data is a different beast altogether
OLAP projects mostly deal with multidimensional data. For instance you can see the below figure, you would like to get sales as per country, customer and date. In simple words you are looking at sales figure which have 3 intersections of dimension data.



Many times I have come across name value tables. Name and value tables means it has key and some data associated with the key. For instance in the below figure you can see we have currency table and country table. If you watch the data closely they actually only have Key and value.

Rule 11:- For unlimited hierarchical data self-reference PK and FK
Many times we come across data with unlimited parent child hierarchy. For instance consider a Multi-level marketing scenario where one sales person can have multiple sales people below them. For such kind of scenarios using a self-referencing primary key and foreign key will help to achieve the same.


You can also visit my site for step by step videos on Design Patterns, UML, SharePoint 2010, .NET Fundamentals, VSTS, UML, SQL Server, MVC and lot more.
No comments:
Post a Comment